I have been involved with testing computer and storage systems for more than 30 years working in a variety of roles, including test engineering, and IT management roles. This is always interesting because by design, you are testing new configurations and finding ways to push a system to its limits. Evaluator Group has been working to develop testing software as well as running functional and performance tests on a variety of products for many years. More recently, we have noted an increased interest in testing object storage systems, due in part to the number of new object systems from vendors, and because of the interest in object storage from IT users.
Evaluator Group recently tested a 5 PB object storage cluster that used Red Hat Ceph 4.1 software, along with components loaned by several Red Hat partners, namely Intel and Seagate. Our testing was designed to prove or dis-prove the premise that a moderately sized Ceph cluster could support up to 10 Billion objects, and do so with consistent performance as the capacity increased up to the designed limits. However, to date there has been very few published performance results from any object storage vendor. The lack of performance data is a significant issue for application developers who have limited information when choosing storage platform for their applications.
Cloud Native Applications
Object storage was originally viewed as an on-line archive for large data sets. As a result, object storage was traditionally used to store large amounts of data, rather than smaller and more latency sensitive data. Although object storage may not meet the needs of transactional database applications requiring low latencies, many applications are finding use for object storage, and in some instances database applications.
One of the reasons developers are using object storage more often is due to the flexibility and the ability to utilize object storage in the same way, regardless of where the application is running. The API driven interface of object storage together with URL access helps to insulate applications from physical boundaries or location restrictions imposed by more traditional block or file access. Thus, we are seeing object storage system being used to retain and persist data for many applications, including those requiring high I/O or object rates.
Many object storage systems claim to provide massive scalability, but then fail to provide any proof of this, or show data that is not readily comparable to any other system. We worked with Red Hat to provide data points that can be directly compared to other object storage systems, using standard testing tools and techniques.
Our Setup
Our test configuration was designed to maximize the processing capabilities of our storage nodes, while also providing high performance for both object I/O and data transfer rates. This meant using several non-standard configuration choices. Many of these decisions are specific to either Ceph or in some cases Red Hat Ceph’s architecture and its requirements.
First, we chose to use two Rados Gateway objects per storage node, rather than a single gateway, in order to handle the high number of objects per second. Next, we used a single bonded network interface for both the Ceph public and private interfaces since we were limited to a single 2×25 Gb/s network card per system. Another non-standard option was to use large, 106 HDD JBOD enclosures, which were then logically split in two. Each of these logical, 53 device enclosures were attached to each Ceph storage node.
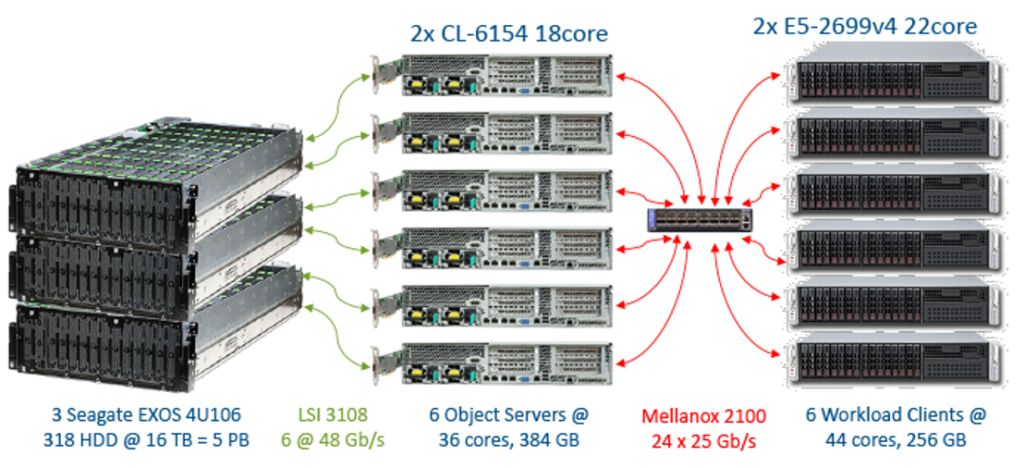
In order to maximize the performance of each Ceph logical object storage device (OSD), we increase the amount of memory assigned to each device to 4 GB. Finally, we used partitioning of NVMe devices to assign an NVMe partition of approximately 820 GB to each OSD as a cache device. This meant that each 16 TB OSD, also had 820 GB of NVMe capacity and 4 GB of DRAM as a cache.
The combination of multiple Rados Gateways along with a 50 Gb network interface enabled both high object per second processing and high bandwidth. The use of a large amount of NVMe and DRAM as cache helped provide the high read performance for both large and small objects.
We have heard many object storage vendors indicate their systems have design limits in the multiple billions of objects, and in some cases no design limitations on the number of objects. However, it is important to note that in many cases, these claims remain un-tested and unproven. It is quite different to actually test a specific systems ability to support 10 Billion objects with consistent performance. There remains a dearth of proof points by object storage vendors for their solutions.
Our Results
Perhaps the most important result was that the configuration used for testing was able to support more than 10 billion objects, but more important than this scale was the fact that object PUT and GET operations were deterministic, providing nearly linear performance as the system capacity grew to over 10 billion objects and 80% of usable capacity. A high-level summary of the performance includes:
- Small, 64 KB objects proved predictable performance
- An average of more than 28,000 objects / sec for GET operations
- An average of more than 17,000 objects / sec for PUT operations
- Large, 128 MB objects attained the following with nearly constant performance
- An average of more than 11.6 GB / sec GET bandwidth
- An average of more than 10.6 GB / sec PUT bandwidth
What We Learned
We found that using default configurations provide a very predictable and easy method to setup a Red Hat Ceph cluster. We chose instead to use a highly customized configuration in order to maximize the server nodes we had available, along with the high-density JBOD HDD enclosures and high capacity NVMe drives. These customizations required assistance with the setup of our configuration in order to optimize the capacity, object rates and throughput of our system.
Red Hat engineering worked with us to calculate expected performance of our configuration based on their past testing and the specific equipment and specification of our system. In the end, the results we achieved were better than the performance calculated during the design of our testing project. However, this also proved that Ceph’s performance for a particular workload is highly predictable and based upon the resources provided.
Although we used a customized setup in order to maximize the equipment we used, we believe we could have achieved nearly the same performance without customization if we had instead utilized more storage nodes. Thus, rather than using 6 high-end nodes, we could have used 12 nodes, with less CPU and memory. However, the storage connectivity would still likely require 40 GB/s connectivity or greater.
It is clear that with the right choice of components, Red Hat’s Ceph can deliver consistent performance, at scale. Our testing showed that it is quite possible to configure a 5 PB Red Hat Ceph storage system using Industry standard servers that can deliver performance to meet the needs of a wide variety of applications.