The advance of Big Data analytics and the need for real time results in application environments such as IoT is driving the need for a new approach to storage. Startups in this space have a particular goal in mind and that is to reduce the latency between the computational layer and the storage layer. Storage must be persistent but long-term persistence commonly comes at a cost to computational performance that makes the delivery of real time analysis difficult at best.
To overcome this debilitating latency, a new approach is to fuse together the memory spaces within nodes in an analytics cluster to create a contiguous memory space across cluster nodes. Direct access memory is indeed a fast way to real time results, but doing so isn’t easy. One of the obstacles to overcome is data consistency across individual memory spaces during computation. Lack of consistency can lead to erroneous results, data corruption and data loss—the impact of which results in angry customers and increased exposure to risk.
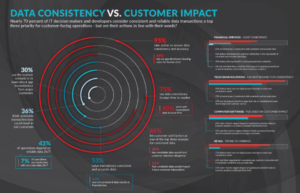
Recent survey data shows how important data consistency across a distributed node-based cluster is to enterprise users. In this survey sponsored by VoltDB, it is not surprising that 95% of enterprise IT decision makers say they take action to ensure data consistency. 75% even go so far as to say that data consistency is more important than time to market.
Two open source projects now gaining increasing traction for real time computing applications are VoltDB for database and Alluxio for file based data.
VoltDB offers an in-memory SQL database that integrates streaming analytics with transactional processing on a distributed cluster computing platform. Processing and data storage functions are distributed among all commodity CPU cores within a VoltDB cluster. Each node operates independently within a shared nothing architecture rather than using shared memory. ACID transaction processing is a bedrock function that is delivered without compromising performance. This assures both developers and users that when records are written to the database and updated, the data is correct and no data is lost.
Alluxio addresses the same set of issues for file system data. In 2012, researchers at the UC Berkeley APM Lab open-sourced a memory-centric, fault-tolerant virtual distributed storage system called Tachyon. Because of its memory-centric design, it found early acceptance when coupled with the Big Data analytics platforms built to deliver real-time or near real-time results such as Apache Spark and Storm. The project was later renamed Alluxio that uses re-computation of log data (referred to as lineage) to provide fault tolerance and data consistency as opposed to creating three distributed copies of data on ingest as is typical with distributed file systems.
I have written before on the coming real time computing wave. I believe that as we experience real time computing we will want more. We are now more likely to get that experience on smart phones as opposed to laptops, but the biggest obstacle is computational latency. In the cases mentioned above, the pioneering work was done by two visionaries. VoltDB was conceived of by Michael Stonebraker working in conjunction with Dan Abadi, Pat Helland, Andy Pavlo, Stan Zdonik and others. Dr. Stonebraker won the 2014 A.M. Turing award, named after Alan Turing who was featured in the movie Imitation Game. A younger UC Berkeley Ph.D. candidate named Haoyuan Li co-created and lead Alluxio (formerly Tachyon) and is also the founder and CEO of Alluxio. Both deserve recognition for their work in removing obstacles on the pathway to real time computing.